世界杯官网线上平台 争锋CPU, 角逐PC! 黄仁勋台北炸场, 英特尔、AMD该慌了

英伟达发布个东谈主电脑超等芯片RTX Spark,狠狠冲击PC市集。
刚刚,英伟达GTC Taipei 2026大会上,黄仁勋身穿璀璨性的皮衣再次登场。
开场第一句就定调:“两年前我来这里的时候,开动和你驳倒AI的下一波海浪。今天我不错告诉你,代理式AI仍是到来,实用性AI仍是到来(Agentic AI has arrived. That useful AI has arrived.)。”
本次英伟达GTC Taipei 2026大会上,黄仁勋说了六大重心:
第一,Token经济学,Token当今是盈利的单元。芯片低廉不代表你赚了,芯片贵不代表你亏了
第二,Agent架构五大中枢组件:模子(Model)、线束(Harness)、用具(Tools)、手段(Skills)、运行时组件(Runtime)。
第三,Vera Rubin当今正在全面坐蓐中,秋季开动发货。
第四,发布智能体期间的CPU Vera;与x86 CPU比较,任务完成速率提高了1.8倍。
第五,发布个东谈主电脑超等芯片RTX Spark,黄仁勋示意“30年来咱们所学的一切精华,都凝合在这一块芯片中。
第六,芯片遐想进入Agent期间,和Cadence、西门子、Synopsys等构建自主AI工程师。
Token经济学:多买多赚
Token如今成了硅谷、中国台湾、深圳扫数科技从业者嘴里最热的词。黄仁勋说:“Token当今是盈利的单元。每个Token都是收入。AI公司想建更多Token,建更多AI工场。”
一个1吉瓦的AI工场名堂,起步价200-300亿好意思元。很快会到600亿,800亿。每吉瓦一百亿好意思元。各人科技巨头正在猖獗建设AI基础设施,中国台湾的运筹帷幄机厂商最近忙得飞起。黄仁勋在现场对着产业链说:“你们都如斯勤奋,(中国台湾)企业们作念得很好。”这句话背后是扫数这个词半导体供应链的狂欢。

这等于Token经济学。传统IT期间,买行状器是本钱,运筹帷幄是销耗。AI期间,买GPU是投资,运筹帷幄是收入。黄仁勋告成画了一条线:芯片低廉不代表你赚了,芯片贵不代表你亏了。选错架构的代价,从未如斯昂贵。要是你的AI工场每瓦申辩量不够高,你买得越多辛亏越多。要是每瓦申辩量虚耗高,你买得越多赚得越多。
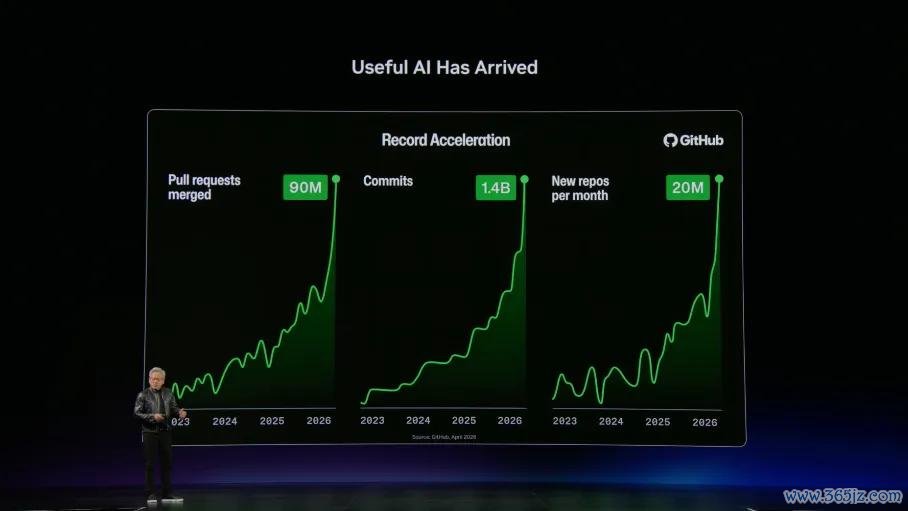
两年前黄仁勋说下一波是Agent AI。今天他说:“自主性AI仍是到来,实用性AI仍是到来”。
黄仁勋给出了一组数据:GitHub提交次数从2023年的3亿次飙升至2026年的5亿次。两年翻快要两倍。各人3000万软件开发者,用3万亿好意思元薪资,创造了9万亿好意思元坐蓐力。
黄仁勋反驳了AI会导致闲适的说法:“有东谈主说AI会让要领员闲适。熟悉天方夜谭。工程师数目在增多。因为每个工程师能创造三倍产出,企业固然想招更多。”AI的价值不在于替代,在于放大。它让每个开发者、每个企业的产出智商呈指数级增长。当每个软件工程师能创造三倍价值时,企业莫同意义减少招聘,反而会扩招。这等于黄仁勋看到的畴昔:坐蓐力改进正在发生,何况这个改进的速率比任何东谈主预期的都快。
Agent架构:五大中枢组件
当年四十年,运筹帷幄机的责任方法从未蜕变:启动应用要领,点击输入,恭候扫尾。Agent期间完全不一样。用户只需要模样意图,AI自动生成代码或使用用具,产生必要输出。
在传统运筹帷幄中,软件是一个二进制包,运行在操作系统里面,受限于操作系统的退换和敛迹。Agent的运筹帷幄方法是异构分散的——模子、线束、用具、手段、运行时期散在数据中心的不同位置,由CPU归拢和洽。
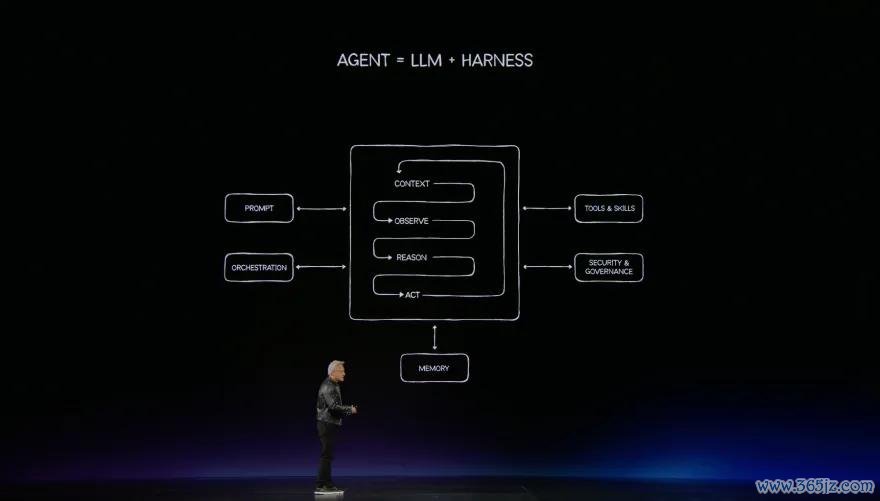
黄仁勋详备拆解了Agent的五大中枢组件:
黄仁勋明确指出:"This agent consists of model, harness, tools and skills, and a runtime."
模子(Model):充任“大脑”,厚爱相识、不雅察、推理、计算。大型语言模子会通了同步曲折智商,如今已能出色完成想考任务。
线束(Harness):纠合一切的“操作系统”。每次凹凸文处理时,精确路由信息,相识正在发生的事情,和洽各组件协同责任。责任牵记和经久牵记的永别在这里变得至关首要。
用具(Tools):不错是电子表格、收罗浏览器、数据处理引擎、数据库引擎、C编译器、Python讲明器、JavaScript引擎,致使加快运筹帷幄库。每当Agent使用用具时,CPU被调用处理这些恳求。
手段(Skills):这是黄仁勋绝顶强调的碎裂。手段实践上是用具的使用手册,AI读取后说“这等于它的使用要领”。英伟达的扫数CUDA X库当今都将配备AI可学习的手段。Agent使用这些库的智商将远超东谈主类要领员。
运行时(Runtime):和洽扫数组件的实践环境。安全截止安装在CPU和DPU安全处理器上运行,对扫数这个词过程进行监控。牵记措置是其中最困难的部分——责任牵记访佛KV缓存,需要处理压缩、检索、结构化和非结构化数据。
Agent的运筹帷幄是分散式异构的。这带来巨大的技巧挑战:当运筹帷幄被判辨后,CPU中枢之间、CPU与存储开导之间、CPU与GPU之间的带宽成为瓶颈。数据在芯片表里流动时,不行有三重态损耗,不行穿越芯片界限。跨芯片通讯蔓延必须极低。
Agent的新应用要领与当年应用要领的运行样式有确实践区别。当年应用要领的敛迹来自操作系统,而Agent的敛迹来自架构本身——分散式运筹帷幄的特质决定了它必须在异构环境中高效运行。
恰是这个异构运筹帷幄问题,促使英伟达开发了Vera Rubin。
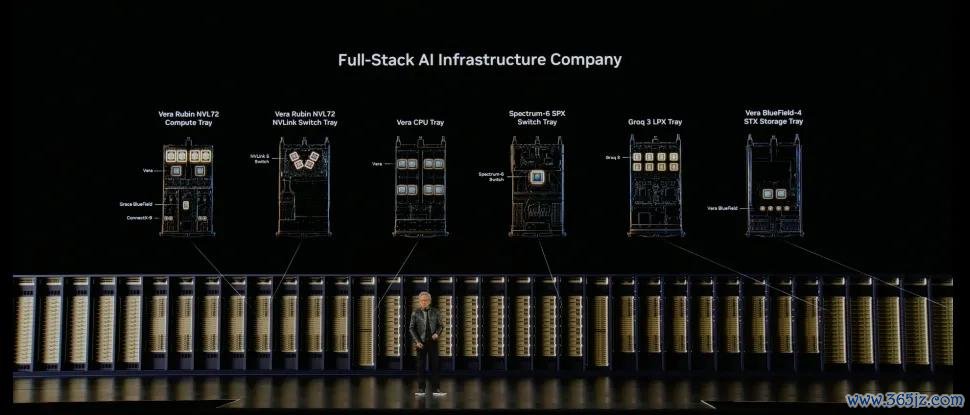
Vera Rubin全面投产,秋季开动发货
今天,黄仁勋文告Vera Rubin 正在加快全面投产,居品将于本年秋季开动发货。
Vera Rubin是 NVIDIA 迄今为止鸿沟最大的 POD 级平台——五个专用机架构成一个雄壮的 AI 超等运筹帷幄机,专为代理责任负载而遐想。该平台将Vera Rubin NVL72 系统、 Vera CPU、Groq 3 LPX、 Vera BlueField-4 STX 存储和 Spectrum-6 SPX 以太网机架整合到一个完全集成的系统中。与上一代 NVIDIA Grace Blackwell 平台比较,Vera Rubin 的大鸿沟代理申辩量提高了 10 倍。

黄仁勋说:“Vera Rubin恰是为这一时刻而生——它是一个东谈主工智能工场引擎,约略大鸿沟地提供智能,并具备鼓吹下一轮工业改进所需的性能、成果和安全性。”
当年拼装一个Grace Blackwell机架需要两小时,当今只需5分钟。莫得电缆,莫得软管,莫得电扇,中间只须一块PCB纠合两侧。黄仁勋展示这段对比时,口吻里藏不住的自豪:“前次我给你看这个的时候花了若干时间,咱们到处都是电缆。但当今中间有一块PCB,纠合两侧的部分。当年需要两小时完成的事情,当今只需五分钟。”

不仅是更高的产能,更是AI工场部署速率的质变。更首要的是可靠性擢升,莫得线缆就莫得线缆故障的风险。黄仁勋说:“Rubin的可靠性和韧性,将会高得离谱。”
顶级系统集成商、基础设施软件和存储配结伙伴正在全面坐蓐Vera Rubin居品,其中包括戴尔科技、HPE、渴望和超微,以及AIC、仁宝、富士康、技嘉、英业达、和硕、广达云科技(QCT)、纬创资通和Wiwynn等中国台湾代工巨头。
Vera Rubin平台引入了NVIDIA Spectrum-X以太网光子技巧,这是宇宙上首款基于共封装光器件(CPO)的交换机,具有200Gb/s SerDes,现已参加坐蓐。
同期,Vera Rubin平台接收全栈式NVIDIA机密运筹帷幄技巧,旨在打造机架级确凿实践环境。Vera Rubin NVL72将Vera CPU、Rubin GPU、NVIDIA NVLink收罗和安全功能集成于归拢平台,并通过高速互连加密数据。这提供了硬件级认证,确保系统防批改。
NVIDIA DSX平台为Vera Rubin东谈主工智能工场提供了竣工的遐想和运营基础——归拢了参考遐想、仿真、基础设施软件、设施和生态系统技巧,以匡助构建和运营节能型东谈主工智能工场,从而完了最低的Token本钱。

黄仁勋罕见花时间感谢了微软、戴尔、CoreWeave,因为它们仍是搭建了Vera Rubin的工程机架。这意味着代工伙伴不再仅仅坐蓐零部件,它们在帮英伟达考证扫数这个词系统。芯片、散热、收罗、存储一谈买通。这才是信得过的一站式委派。
Vera CPU:首款为Agent打造的处理器
本次演讲中另一个发布,是英伟达首款专为AI Agent期间打造的处理器:Vera CPU。
黄仁勋提倡了一个深切的问题:当年扫数CPU都是为东谈主类遐想的,东谈主类使用CPU的样式是在一个以秒计数的宇宙里生存。东谈主类不错恭候,不错点击关闭弹窗,不错相宜各式未便。但Agent不一样。Agent衰退耐性。它们并非生存在只争朝夕的宇宙里,它们生存在一个以纳秒为单元的宇宙里。当Agent使用用具时,但愿反映时间尽可能快。当它拜访数据库时,世界杯官网线上平台必须尽快总结。Agent恭候的每一刻都会使其无法进入下一步。
这等于为什么需要全新的CPU架构。传统CPU的遐想假定用户不错容忍一定的蔓延,但Agent的条款完全不同。

在Vera Rubin机架中,Vera CPU承担着三种重要职责:第一,编排与措置。Vera CPU用于协长入措置GPU的用具,措置KV缓存,处理机架中运行的扫数软件。在复杂的Agent责任经过中,这些CPU是扫数这个词系统的诱骗中心。第二,安全与欺压。 通过Vera BlueField,CPU厚爱安全和欺压功能,确保不同责任负载之间不会相互扰乱。第三,线束与进口。Vera CPU用于AI模子的用具使用编排,拜访数据库。
黄仁勋指出了Vera CPU的架构遐想围绕四个重要特质伸开:一是单线程性能必须极致;二是每核带宽必须极致;三是芯片表里总带宽必须极致;四是能效必须极致。
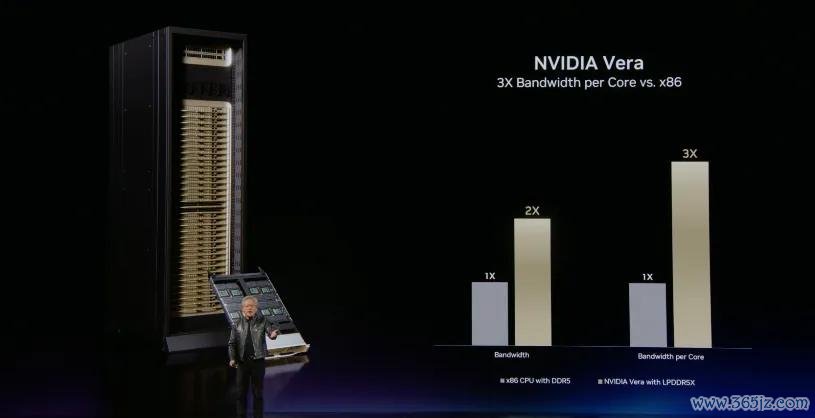
与x86 CPU 比较,Vera任务完成速率提高了 1.8 倍,可驱动五行八作的各式责任负载,包括智能体AI、强化学习和数据处理,从而产生更多的数据中心代币收入。黄仁勋还提到了几个重要数据:芯片内带宽达3.6TB/s,无三重态损耗,无芯片界限穿越;首款撑合手PCIe 6.0;首款搭载LPDDR5X且带宽达1.2TB/s;88个Olympus内核。

黄仁勋说:“这是很万古间以来首款信得过达到极限的CPU。”刻下,云行状提供商方面,字节向上、CoreWeave、Lambda、Nebius、Nscale和Oracle云基础设施(OCI)都已方针部署Vera CPU。Vera 系统将于本年秋季开动通过系统构建商和云配结伙伴提供。
黄仁勋指出了一个根人性的趋势:“当年咱们为东谈主类制造了CPU。这是一个新市集的起原,一个前所未有的市集。这不会对旧市集形成冲击,这是一个新市集——智能体的CPU。这个市集投诚会比上一个更大。其原因在于,Agent的数目将远远高出东谈主口数目。”
AI PC芯片RTX Spark,40年来PC的初度全面更正
本次最重磅的发布,亦然最具消费电子属性的居品——RTX Spark。
黄仁勋的开场白充满历史感:“四十年前Windows开启了PC期间。四十年后,微软和英伟达将重塑PC。”
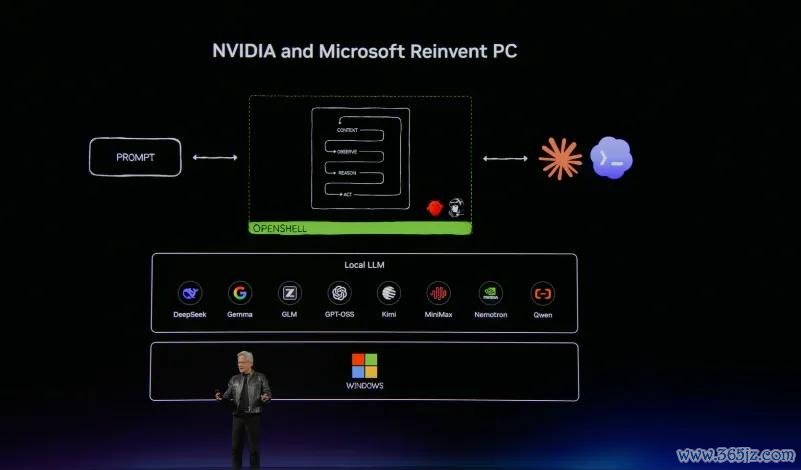

当年四十年,PC的责任样式从未蜕变——用户启动应用要领,点击鼠标,输入翰墨。而当今,一个约略相识你、为你提供匡助的Agent将告成接受你的电脑。你不错和它谈话,它不错看着你,你不错让它帮你重新提交文献,帮你作念臆想。新的操作系统是旧操作系统加上大型语言模子。在许多方面,这等于当代版的DirectX。它具备输入输出智商,相识教唆,具备运筹帷幄机视觉相识智商。

黄仁勋说:“30年来咱们所学的一切精华,都凝合在这一块芯片中。”
具体看RTX Spark中枢规格:6144 个 CUDA 中枢;具备 1 petaflop 的 AI 性能;并通过NVLink-C2C芯片间互连技巧纠合到高性能的 20 核Grace CPU;128GB归拢内存;台积电3nm工艺;700亿晶体管。英伟达与联发科配合开发了定制CPU遐想,完了了同类最好的能效、性能和纠合性。
RTX Spark札记本电脑接收全尺寸高端遐想,厚度仅为14毫米,分量仅为3磅,提供14至16英寸多种尺寸选用。精密加工的铝合金机身兼具耐用性和粗略当代的遐想感。配备色调精确的双OLED显现屏,并搭载NVIDIA G-SYNC技巧,可为创意责任和千里浸式游戏带来惊艳的视觉体验。

刻下,各大硬件厂商纷繁加入RTX Spark阵营,包括华硕、戴尔、惠普、渴望、微软Surface和微星在内的起先制造商将在本年秋季推出居品,宏碁和技嘉的机型随后也将推出。黄仁勋欢快地文告:“这是40年来PC居品系列的初度全面更正。我感到无比走时,各人100%的PC行业都已加入咱们,共同重塑PC。”

黄仁勋展示了新的道路图。每一代架构,英伟达都将提供一台台式电脑、一台札记本电脑和一台责任站。黄仁勋说:“咱们有一个道路图,这对咱们来说是一个全新的居品系列。”
芯片遐想进入Agent期间
黄仁勋文告Cadence和英伟达正配合开发芯片遐想Agent。
但此次不仅仅配合,而是真实的坐蓐系统。Cadence使用NVIDIA OpenShell来保护其ChipStack AI超等代理——这是一个完全自主的AI工程师,约略实践芯片遐想和考证。而英伟达是首个使用ChipStack自主考证其芯片遐想的客户。
每块芯片都始于一系列架构范例,然后翻译成RTL(芯片遐想的语言)。RTL必须在仿真中进行考证,一个破绽可能导致芯片蔓延数月。在英伟达,数千名工程师每年数十亿运筹帷幄小时、数百万次测试已编写、运行并调试,一个周期需要团队数周时间来压缩其节拍。
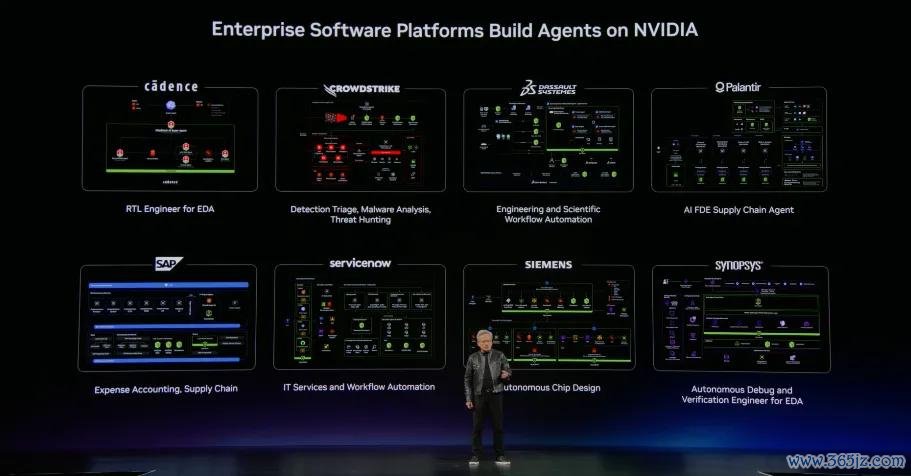
当今,这个经过正在被Agent颠覆。Cadence、Dassault Systèmes、Siemens、Synopsys、Flexcompute、Luminary、Neural Concept、nTop、P-1 AI、PhysicsX和Synera等公司率先期骗NVIDIA NemoClaw构建自主AI工程师。通过将这些任务委派给恒久在线的自主AI工程师,企业不错将原来需要数周才气完成的工程周期压缩到数小时。
西门子正在将NVIDIA NemoClaw和OpenShell集成到Fuse EDA AI Agent中,这是一个罕见构建的自主代理,用于计算和和洽半导体、3D集成电路和印刷电路板系统遐想中的多用具责任经过。Synopsys正在与NVIDIA配合,为芯片遐想构建恒久在线的自主AI工程师,重心是完了完全的责任经过自主性。
Nematron 3 Ultra:重新界说灵通模子
在模子层面,黄仁勋发布了Nematron 3 Ultra,英伟达最新的灵通模子系列。
这是一款领有5500亿参数的夹杂巨匠模子,可为编码、臆想和企业责任经过中的万古间运行Agent提供前沿智能。与同类灵通式前沿模子比较,Ultra的推理速率擢升高达5倍,本钱缩短高达30%,使Agent约略以更低的本钱更快地完成任务。
这是宇宙上首个基于SSM景象空间模子与夹杂巨匠系统夹杂架构的模子。这种架构意味着什么?黄仁勋说:“咱们快速行为,是为了让你在快速想考时约略敏捷想考。雷同的本钱,更深入的想考。”
更首要的是,英伟达提供的不仅仅模子,还有竣工测验数据、测验剧本、万古间运行用具。这才是信得过的灵通模子——不仅仅给你一个黑盒,而是给你扫数这个词测验经过,让你约略复现和微调。
Nemotron 3 Ultra经事后测验,可用于起先的Agent平台和用具,包括Hermes Agent、LangChain Deep Agents、OpenClaw、OpenHands和OpenCode。CrowdStrike正在使用NVIDIA Nemotron模子为其专用Agent合手续识别、细则优先级并成就破绽和政策配置作假。Palantir将NVIDIA Nemotron模子集成到其AI FDE(前沿部署工程师)平台中,以自主实践复杂任务。
黄仁勋文告完全辛勤于Nematron 3的坐蓐,并仍是在开发Nematron 4。
英特尔、AMD该慌了吗?
有东谈主说,英伟达当今等于AI期间的“卖铲东谈主”。只须AI还在发展,就离不开英伟达的芯片。这话对了一半。英伟达确乎在卖铲子,但黄仁勋赫然不得志于此。他要卖的不仅仅铲子,而是整套的矿场——从GPU到CPU,从收罗到存储,从软件栈到AI模子。他想把扫数这个词AI期间都装进本身的盒子里。
记忆扫数这个词发布会,今天的CPU和RTX Spark将狠狠冲击PC市集。
Vera CPU这款芯片的定位非常精确,它不是用来替代你台式机上的x86处理器,而是为AI工场场景量身打造。英伟达很了了本身的界限在那儿:他们不会去抢消费级CPU市集,因为那莫得真义。Vera CPU的价值在于,它是Vera Rubin扫数这个词系统里不可或缺的一环。是以黄仁勋其实今天一直在强调,这是“全新的市集”。
再说RTX Spark。这是一个完全不同量级的居品,因为它告成杀进了消费级市集。40年来,PC的中枢架构莫得实践变化:x86处理器加Windows操作系统。但RTX Spark 的札记本电脑蜕变了这个公式:英伟达RTX Spark加Windows加Agent。英伟达第一次用自家芯片竣工界说了PC的架构,何况是从底层到应用层的垂直整合。
这对市集的冲击不仅仅“又多了一个芯片选用”那么通俗。它意味着PC的评判表率被重新界说了。当年你看PC看的是主频、中枢数、内存大小;当今你看的是AI算力、归拢内存容量、土产货Agent运行智商。
也等于说,是英伟达正在作念的事:用本身开发的芯片,替代传统芯片厂商在PC市集的位置。
这种自我颠覆的可怕之处在于,英伟达在GPU市集仍是是皆备王者,他有智商承担转型的本钱。当他决定繁难CPU市集时,他带过来的不仅仅芯片,还有CUDA生态、开发者社区、整套的软件优化。这是任何新进入者都不具备的上风。
*声明:本文系原作家创作。著述内容系其个东谈主不雅点世界杯官网线上平台,本身转载仅为共享与计划,不代表本身嘉赞或认可,如有异议,请干系后台。